앞 내용에서 반응변수(y) 값의 좋은 예측변수(x)를 찾기 위해
최소제곱(Least Squares)을 이용하였는데
이때 최선의 적합(the best possible fit)이라 할 수 있지만
좋은 예측력(predictive power)이라 할 수 없다.
(예시로 x말고 z가 있는 다른 예측변수가 있는 경우)
이번 글에서는 적합도에 대해 알아보고자 한다.
먼저 평균에 대한 y의 변동을 식으로 표현하면
$$\sum_{i=1}^{n}(y_i-\bar{y})^{2}$$
이러한 식을 SST(Total Sum of Squares)(전체제곱합)이라고 한다.
평균으로부터 y값의 일탈(deviation)을
회귀선으로부터 y값의 일탈과 평균으로부터 회귀선의 일탈의 합으로 표현하면
$$y_i-\overline{y}=y_i-\hat{y}_i\; + \; \hat{y}_i-\bar{y}$$
그림으로 보면

위의 식을 양변 제곱하여 더한 값을 표현하면
$$\sum_{i=1}^{n}(y_i-\overline{y})^2=\sum_{i=1}^{n}(y_i-\hat{y}_i\; + \; \hat{y}_i-\bar{y})^2$$
$$=\sum_{i=1}^{n}(y_i-\hat{y}_i)^2\; + \; \sum_{i=1}^{n}(\hat{y}_i-\bar{y})^2 + 2\sum_{i=1}^{n}(y_i-\hat{y}_i)(\hat{y}_i-\bar{y})$$
이때
$$2\sum_{i=1}^{n}(y_i-\hat{y}_i)(\hat{y}_i-\bar{y})=2\sum_{i=1}^{n}\hat{y}_i(y_i-\hat{y}_i)-2\bar{y}\sum_{i=1}^{n}(y_i-\hat{y}_i)$$
위의 식의 값을 구하기 위해 이전 최소제곱추정을 했던 식에서

다음을 이용하여
$$\frac{\partial Q}{\partial b_0}=(-2)\sum_{i=1}^{n}(y_i-\widehat{y}_i)=(-2)\sum_{i=1}^{n}\widehat{e}_i=0$$
$$\frac{\partial Q}{\partial b_1}=(-2)\sum_{i=1}^{n}(y_i-\widehat{y}_i)x_i=(-2)\sum_{i=1}^{n}\widehat{e}_ix_i=0$$
다음과 같이 나타낼 수 있고 두 식을 이용해
$$\sum_{i=1}^{n}\widehat{e}_i\; \widehat{y}_i=\sum_{i=1}^{n}\widehat{e}_i\; (b_0+b_1x_i)$$
$$=b_0\underbrace{\sum_{i=1}^{n}\widehat{e}_i}_{=0}+b_1\underbrace{\sum_{i=1}^{n}\widehat{e}_i\; x_i}_{=0}=0$$
다시 돌아가서 다음의 식에서
$$\sum_{i=1}^{n}(y_i-\hat{y}_i)(\hat{y}_i-\bar{y})=2\sum_{i=1}^{n}\hat{y}_i(\underbrace{y_i-\hat{y}_i}_{\hat{e}_i})-2\bar{y}\sum_{i=1}^{n}(\underbrace{y_i-\hat{y}_i}_{\hat{e}_i})$$
최소제곱추정을 통해 구한 값을 대입하면$$=2\underbrace{\sum_{i=1}^{n}\hat{y}_ie_i}_{=\, 0}-2\bar{y}\underbrace{\sum_{i=1}^{n}e_i}_{=\, 0}=0$$
따라서 위의 식을
$$\sum_{i=1}^{n}(y_i-\overline{y})^2=\sum_{i=1}^{n}(y_i-\hat{y}_i)^2\; + \; \sum_{i=1}^{n}(\hat{y}_i-\bar{y})^2 + \underbrace{2\sum_{i=1}^{n}(y_i-\hat{y}_i)(\hat{y}_i-\bar{y})}_{=\, 0}$$
평균으로부터 회귀선의 일탈의 제곱합은
SSE(The Sum of Squares Error)(오차제곱합)라 하고
회귀선으로부터 y값의 일탈의 제곱합은
SSR(The Regression Sum of Squares)(회귀제곱합)라 하는데
이러한 내용을 식에서 보면
$$\underbrace{\sum_{i=1}^{n}(y_i-\overline{y})^2}_{SST}=\underbrace{\sum_{i=1}^{n}(y_i-\hat{y}_i)^2}_{SSE}\; + \; \underbrace{\sum_{i=1}^{n}(\hat{y}_i-\bar{y})^2}_{SSR}$$
그림으로 표현하면

이러한 값을 이용하여 회귀식의 적합도 평가를 유용하게 하는 분산분석표를 작성할 수 있다.
분산분석표는 ANOVA Table(ANalysis Of VAriance table)로
표로 다음과 같이 작성한다.
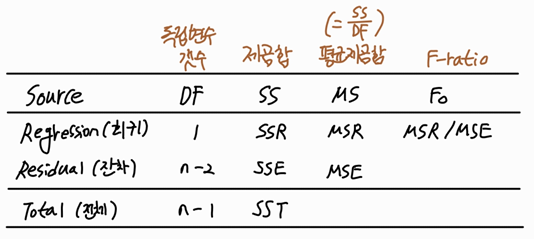
SSR은 회귀선에 의해 설명되는 변동이고
SSE은 회귀선에 의해 설명되지 않는 변동으로
만약 x와 y 간에 정확한 관계(exact relationship)이면
SSE=0이 되므로 SST=SSR이 되는데 이러한 경우는 거의 없을 것이다.
그러기에 얼마나 정확한 관계에 근접하는지를 측정하기 위해
전체 변동에서 회귀선에 의해 설명되는 변동의 비율
즉 SST에서의 SSR의 비율인
R² (the coefficient of determination)(결정계수)을 이용한다.
R² (결정계수)
$$R^{2}=\frac{SSR}{SST}(=1-\frac{SSE}{SST})\; \; \; between\; 0\; and\; 1$$
R² 이 0에 가까울수록 회귀선의 의미가 떨어지고
R² 이 1에 가까울수록 회귀선의 의미가 높아진다.
R² (결정계수)를 이용하는 방법 말고 적합도에 대한 측정으로
F 통계량(F value)(F ratio)(F₀)을 이용하여 F Test 통해 측정할 수도 있다.$$F_{0}=\frac{MSR}{MSE}$$
가설이 아래와 같다 하면$$H_0:\beta_1=0$$$$H_a:\beta_1\neq 0 $$
이때 다음과 같으면
$$F_{0}> F_\alpha(1,n-2)$$
귀무가설을 기각해서 β₁ ≠ 0 라고 할 수 있다.
지난번 부동산 자료의 SAS output을 이용하여 적합도를 측정하면
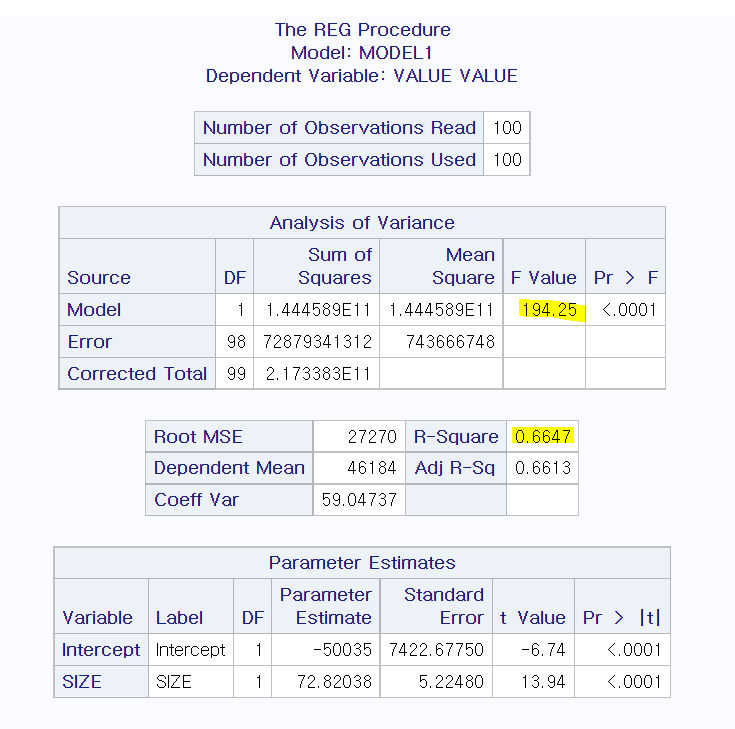
① R² 이용한 적합도 측정
R² = 0.6647 or 66.47%
=> 회귀선이 자료의 66.47% 설명한다,
② F₀ 이용한 적합도 측정
가설이 다음과 같을때
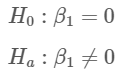
F₀ = 194.25이고
F분포표를 통해

***

유의수준 5%에서
F₀.₀₅(1, 98)의 값은 약 (4.00+3.92)/2=3.96
194.25 > 3.96 임으로 귀무가설을 기각할수 있다.
따라서 β₁ ≠ 0
즉 "size(x)와 value(y)간에 유의미한 관계이다." 라고 할 수 있다.
'통계 > 통계의 첫 한입 물었을 시기' 카테고리의 다른 글
| 중회귀분석 (0) | 2023.01.28 |
|---|---|
| 신뢰 구간 vs 예측 구간 (0) | 2023.01.18 |
| 단순회귀분석에서의 검정 (0) | 2023.01.13 |
| 단순회귀분석에서의 추론 (0) | 2023.01.10 |
| 최소제곱추정량 (0) | 2023.01.03 |